
 Justin Tracey
afdd747eb6
inital grading-on-a-curve commit
Justin Tracey
afdd747eb6
inital grading-on-a-curve commit
|
2 anni fa | |
|---|---|---|
| .. | ||
| data_assembler | 8 anni fa | |
| doc | 7 anni fa | |
| examples | 7 anni fa | |
| fetch_bugzilla_bugs | 2 anni fa | |
| fetch_jira_bugs | 2 anni fa | |
| learning_curves | 2 anni fa | |
| model | 8 anni fa | |
| szz | 2 anni fa | |
| .gitignore | 6 anni fa | |
| Dockerfile | 7 anni fa | |
| LICENSE | 8 anni fa | |
| README.md | 6 anni fa | |
| author-identities.py | 2 anni fa | |
| bugcounts.sh | 2 anni fa | |
| compare_results-v2.sh | 2 anni fa | |
| compare_results.sh | 2 anni fa | |
| reproduceResults.sh | 2 anni fa | |
| workflow.png | 7 anni fa | |
{kind=link}
README.md
SZZ Unleashed
SZZ Unleashed is an implementation of the SZZ algorithm, i.e. an approach to identify bug-introducing commits, introduced by Śliwerski et al's in "When Do Changes Induce Fixes?", in Proc. of the International Workshop on Mining Software Repositories, May 17, 2005. The implementation uses "line number mappings" as proposed by Williams and Spacco in "SZZ Revisited: Verifying When Changes Induce Fixes", in Proc. of the Workshop on Defects in Large Software Systems, July 20, 2008.
This repository responds to the call for public SZZ implementations by Rodríguez-Pérez, Robles, and González-Barahona. "Reproducibility and Credibility in Empirical Software Engineering: A Case Study Based on a Systematic Literature Review of the use of the SZZ Algorithm", Information and Software Technology, Volume 99, 2018.
If you find SZZ Unleashed useful for your research, please cite our paper:
- Borg, M., Svensson, O., Berg, K., & Hansson, D., SZZ Unleashed: An Open Implementation of the SZZ Algorithm - Featuring Example Usage in a Study of Just-in-Time Bug Prediction for the Jenkins Project. In Proc. of the 3rd ACM SIGSOFT International Workshop on Machine Learning Techniques for Software Quality Evaluation (MaLTeSQuE), pp. 7-12, 2019. arXiv preprint arXiv:1903.01742.
Table of Contents
- Background
- Running SZZ Unleashed
- SZZ Unleashed with Docker
- Example Application: Training a Classifier for Just-in-Time Bug Prediction
- Examples and executables
- Authors
Background
The SZZ algorithm is used to find bug-introducing commits from a set of bug-fixing commits. The bug-introducing commits can be extracted either from a bug tracking system such as Jira or simply by searching for commits that state that they are fixing something. The identified bug-introducing commits can then be used to support empirical software engineering research, e.g., defect prediction or software quality. As an example, this implementation has been used to collect training data for a machine learning-based approach to risk classification of individual commits, i.e., training a random forest classifier to highlight commits that deserve particularily careful code review. The work is described in a MSc. thesis from Lund University (in press).
Running SZZ Unleashed
Building and running SZZ Unleashed requires Java 8 and Gradle. Python is required to run the supporting scripts and Docker must be installed to use the provided Docker images. All scripts and compilations has been tested on Linux and Mac, and partly on Windows 10.
The figure shows a suggested workflow consisting of four steps. Step 1 and Step 2 are pre-steps needed to collect and format required data. Step 3 is SZZ Phase 1, i.e., identifying bug-fixing commits. Step 4 is SZZ Phase 2, i.e., identifying bug-introducing commits. Steps 1-3 are implemented in Python scripts, whereas Step 4 is implemented in Java.
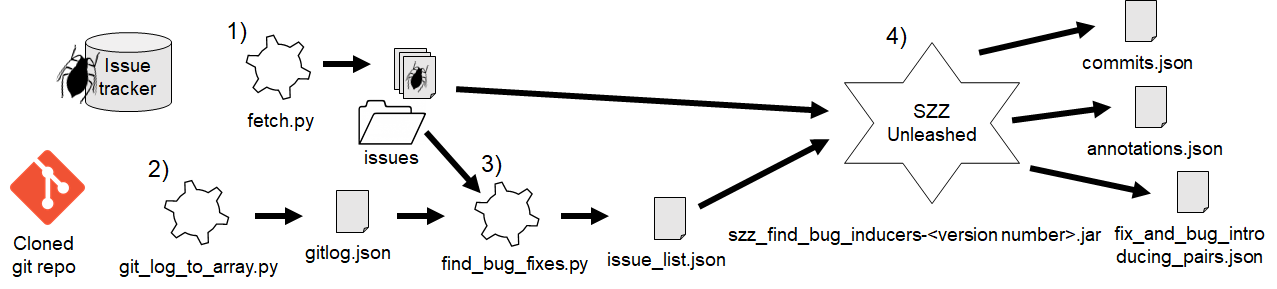
Step 1. Fetch issues (SZZ pre-step)
To get issues one needs a bug tracking system. As an example the project Jenkins uses Jira. From here it is possible to fetch issues that we then can link to bug fixing commits.
We have provided an example script that can be used to fetch issues from Jenkins issues (see 1 in the figure). In the directory fetch_jira_bugs, one can find the fetch.py script. The script has a jql string which is used as a filter to get certain issues. Jira provides a neat way to test these jql strings directly in the web page. Change to the advanced view and then enter the search criteria. Notice that the jql string is generated in the browser's url bar once enter is hit.
To fetch issues from Jenkins Jira, just run:
python fetch.py --issue-code <issue_code> --jira-project <jira_project_base_url>
passing as parameters the code used for the project issues on Jira and the name of the Jira repository of the project (e.g., issues.jenkins-ci.org). The script creates a directory with issues (see issues folder in the figure). These issues will later on be used by the find_bug_fixes.py script.
A more thorough example of this script can be found here.
Step 2. Preprocess the git log output (SZZ pre-step)
Second we need to convert the git log output to something that can be processed. That requires a local copy of the repository that we aim to analyze, Jenkins Core Repository. Once cloned, one can now run the git_log_to_array.py script (see 2 in the figure). The script requires an absolute path to the cloned repository and a SHA-1 for an initial commit.
python git_log_to_array.py --from-commit <SHA-1_of_initial_commit> --repo-path <path_to_local_repo>
Once executed, this creates a file gitlog.json that can be used together with issues that we created with the fetch.py script.
An example of this script and what it produces can be found in the examples.
Step 3. Identify bug-fixing commits (SZZ Phase 1)
Now, using the find_bug_fixes.py (see 3 in the figure) and this file, we can get a json file
that contains the issue and its corresponding commit SHA-1, the commit date, the creation date and the resolution date. Just run:
python find_bug_fixes.py --gitlog <path_to_gitlog_file> --issue-list <path_to_issues_directory> --gitlog-pattern "<a_pattern_for_matching_fixes>"
The output is issue_list.json which is later used in the SZZ algorithm.
An example output of this script can be found in the examples.
Identify bug-introducing commits (SZZ Phase 2)
This implementation works regardless which language and file type. It uses JGIT to parse a git repository.
To build a runnable jar file, use the gradle build script in the szz directory like:
gradle build && gradle fatJar
Or if the algorithm should be run without building a jar:
gradle build && gradle runJar
The algorithm tries to use as many cores as possible during runtime.
To get the bug introducing commits from a repository using the file produced by the previous issue to bug fix commit step, run (see 4 in the figure):
java -jar szz_find_bug_introducers-<version_number>.jar -i <path_to_issue_list.json> -r <path_to_local_repo>
Output from SZZ Unleashed
As shown in the figure, the output consists of three different files: commits.json,
annotations.json and fix_and_bug_introducing_pairs.json.
The commits.json file includes all commits that have been blamed to be bug
introducing but which haven't been analyzed by anything.
The annotations.json is a representation of the graph that is generated by the
algorithm in the blaming phase. Each bug fixing commit is linked to all possible
commits which could be responsible for the bug. Using the improvement from
Williams et al's, the graph also contains subgraphs which gives a deeper search
for responsible commits. It enables the algorithm to blame other commits than
just the one closest in history for a bug.
Lastly, the fix_and_bug_introducing_pairs.json includes all possible pairs
which could lead to a bug introduction and fix. This file is not sorted in any
way and it includes duplicates when it comes to both introducers and fixes. A
fix can be made several times and a introducer could be responsible for many
fixes.
Configuring SZZ Unleashed
A description of how to configure SZZUnleashed further can be found in the examples.
Use SZZ Unleashed with Docker
A more thorough instruction in using Docker to produce the results can be found in doc/Docker.md. Below is a very brief instruction.
There exists a Dockerfile in the repository. It contains all the steps in chronological order that is needed to generate the fix_and_bug_introducing_pairs.json. Simply run this command in the directory where the Dockerfile is located:
docker build -t ssz .
Then start a temporary docker container:
docker run -it --name szz_con szz ash
In this container it is possible to study the results from the algorithm. The results are located in ./szz/results.
Lastly, to copy the results from the container to your own computer run:
docker cp szz_con:/root/szz/results .
Note that the temporary container must be running while the docker cp command is executed. To be sure, check that the szz_con is listed when running:
docker ps
Example Application: Training a Classifier for Just-in-Time Bug Prediction
To illustrate what the output from SZZ Unleashed can be used for, we show how to train a classifier for Just-in-Time Bug prediction, i.e., predicting if individual commits are bug-introducing or not. We now have a set of bug-introducing commits and a set or correct commits. We proceed by representing individual commits by a set of features, based on previous research on bug prediction.
Code Churns
The most simple features are the code churns. These are easily extracted by just parsing each diff for each commit. The ones that are extracted are:
- Total lines of code - Which simply is how many lines of code in total for all changed files.
- Churned lines of code - This is how many lines that have been inserted.
- Deleted lines of code - The number of deleted lines.
- Number of Files - The total number of changed files.
To get these features, run: python assemble_code_churns.py <path_to_repo> <branch>
Diffusion Features
The diffusion features are:
- The number of modified subsystems.
- The number of modified subdirectories.
- The entropy of the change.
To extract the diffusion features, just run:
python assemble_diffusion_features.py --repository <path_to_repo> --branch <branch>
Experience Features
Maybe the most sensitive feature group. The experience features are the features that measure how much experience a developer has, calculated based on both overall activity in the repository and recent activity.
The features are:
- Overall experience.
- Recent experience.
The script builds a graph to keep track of each authors experience. The initial
run is:
python assemble_experience_features.py --repository <repo_path> --branch <branch> --save-graph
This results in a graph that the script below uses for future analysis
To rerun the analysis without generating a new graph, just run:
python assemble_experience_features.py --repository <repo_path> --branch <branch>
History Features
The history is represented by the following:
- The number of authors in a file.
- The time between contributions made by the author.
- The number of unique changes between the last commit.
Analogous to the experience features, the script must initially generate a graph
where the file meta data is saved.
python assemble_history_features.py --repository <repo_path> --branch <branch> --save-graph
To rerun the script without generating a new graph, use:
python assemble_history_features.py --repository <repo_path> --branch <branch>
Purpose Features
The purpose feature is just a binary feature representing whether a commit is a fix or not. This feature can be extracted by running:
python assemble_purpose_features.py --repository <repo_path> --branch <branch>
Coupling
A more complex type of features are the coupling features. These indicate how strong the relation is between files and modules for a revision. This means that two files can have a relation even though they don't have a relation inside the source code itself. By mining these, features that give indications of how many files that a commit actually has made changes to are found.
The mining is made by a Docker image containing the tool code-maat.
Note that calculating these features is time-consuming. They are extracted by:
python assemble_features.py --image code-maat --repo-dir <path_to_repo> --result-dir <path_to_write_result>
python assemble_coupling_features.py <path_to_repo>
It is also possible to specify which commits to analyze. This is done with the
CLI option --commits <path_to_file_with_commits>. The format of this file is
just lines where each line is equal to the corresponding commit SHA-1.
If the analysis is made by several Docker containers, one has to specify
the --assemble option which stands for assemble. This will collect and store
all results in a single directory.
The script can check if there are any commits that haven't been
analyzed. To do that, specify the --missing-commits option.
Classification
Now that all features have been extracted, the training and testing of the machine learning classifier can be made. In this example, we train a random forest classifier. To do this, run the model script in the model directory:
python model.py train
Examples and executables
In the examples directory, one can find documents containing descriptions about each script. There is also a data directory containing data produced by the scripts. It can be used to either study how the output should look like or if anyone just wants a dataset to train on.